




In un recente report pubblicato lo scorso giugno e riferito al comportamento degli utenti italiani online, Audiweb indica che il 92,4% utilizza un motore di ricerca, confermando che la ricerca di informazioni su internet è una delle più popolari attività online. Il market share dei motori di ricerca a livello mondo, come risulta dalle statistiche NetMarketShare, ha visto nel 2015 al primo posto Google con il 66,41%, seguito dal cinese Baidu col 12,33%, Bing al 10,16% e Yahoo all’ 8,76%. Esiste però una più netta prevalenza di Google nei mercati americani e dell’Europa occidentale, mentre nei Paesi come la Cina e la Russia prevalgono i motori di ricerca locali.
I motori di ricerca sono sistemi complessi, che incorporano tecnologie avanzate, i cui dettagli sono riservati e protetti dai singoli fornitori a fini concorrenziali. Comprendono molteplici componenti che svolgono funzioni specializzate e cooperano tra di loro al fine di soddisfare le richieste degli utenti, ottimizzando la qualità dei risultati forniti e i tempi di risposta.
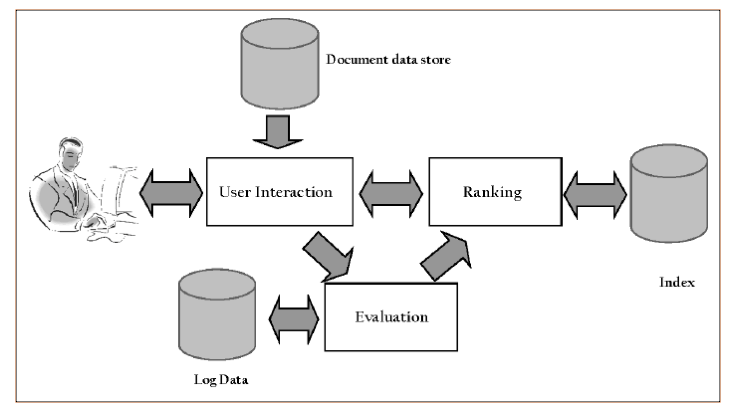
Da un punto di vista funzionale, è possibile individuare due processi distinti: il processo di indicizzazione e il processo di ricerca. Il primo costruisce e mantiene aggiornata le strutture che rendono possibile la ricerca (operando fuori linea, in maniera invisibile agli utenti), il secondo utilizza queste strutture e la richiesta di ricerca di un utente (in tempo reale, al momento della richiesta) per produrre una lista ordinata dei risultati di ricerca, presentando per primi quelli con un ranking più elevato. I due processi sono schematizzati nelle figure seguenti.
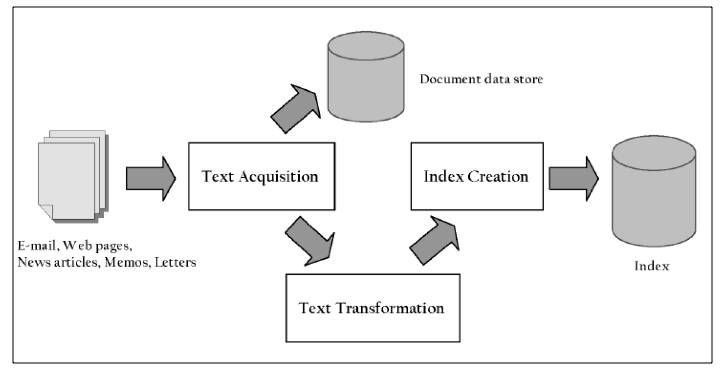
Il processo di indicizzazione comprende varie fasi. Internet viene scandagliato da programmi chiamati crawler, che identificano e raccolgono ogni tipo di informazione presente su internet (pagine di testo HTML, documenti nei vari formati, immagini, video, ecc.), seguendo il flusso dei link tra le pagine web. Non tutto ciò che è presente su internet riesce a essere identificato (per esempio pagine non collegate e pagine in siti ad accesso controllato), costituendo quello che è definito il web invisibile o deep web, la cui dimensione è incerta, ma valutata almeno pari al web visibile. La documentazione raccolta viene interamente copiata in grandi database (insieme a informazioni accessorie come tipo di documento, origine, link, data di creazione, lunghezza, ecc.), una vera e propria copia del web, e quindi classificata, corredata da un’analisi statistica del contenuto e dei link (ranking statico), trasformata in termini di testo (token) tali da essere indicizzati (database degli indici) per indirizzare il database dei documenti. A causa dell’enorme volume di dati i database, comprensivi degli indici, sono giganteschi e per motivi prestazionali sono distribuiti in tutto il mondo. Nel 2012 Google ha creato un nuovo sito dove presenta la struttura, la tecnologia, gli sforzi per l’efficienza energetica e la sicurezza dei suoi data center, offrendo anche la possibilità di un tour virtuale all’interno di uno di essi. Una stima del 2011 di Koomey indica in 900.000 (ma ovviamente i numeri sono ora sensibilmente maggiori) i server Google distribuiti nei suoi 15 attuali data center in America, Europa e Asia.
Il processo di ricerca si attiva al momento in cui l’utente inserisce la sua ricerca (query) nella pagina web del motore di ricerca. L’utente è assistito nella formulazione della query con controlli sintattici, varianti e suggerimenti, che tengono conto anche del suo profilo comportamentale (la storia delle sue ricerche passate, i suoi interessi, le sue preferenze, i siti web visitati, ecc.) memorizzato nel log data. La query, raffinata e ottimizzata per meglio interpretare la ricerca desiderata, viene trasformata in termini di ricerca, che sono poi confrontati (tecniche booleane) con il database degli indici, per individuare le corrispondenze e quindi i documenti del database dei documenti che soddisfano la ricerca dell’utente. Algoritmi di ranking, sulla base del ranking statico dei documenti e del ranking dinamico (aderenza dei termini di ricerca, profilo comportamentale dell’utente, la sua localizzazione geografica, la data e ora della query, ecc.), determinano la relativa importanza dei documenti individuati e quindi l’ordine di preferenza con cui i risultati della ricerca sono presentati all’utente. Ogni elemento della lista presentata contiene i link alle pagine web reali di internet (sui server dove risiedono, non alla copia nel database del motore di ricerca), con un breve sommario del contenuto (snippet), parole significative evidenziate, opzioni di traduzione e eventuali riferimenti pubblicitari (online behavior advertising). Tutto il processo di ricerca si definisce e presenta all’utente i risultati di milioni di pagine web in frazioni di secondo.
Questa sommaria descrizione dei motori di ricerca ne evidenzia caratteristiche fondamentali: l’ampiezza delle informazioni che recuperano dal web, l’efficienza dell’indicizzazione, la velocità, il tracciamento dei dati degli utenti, il profiling comportamentale, la rilevanza dei meccanismi di ranking nel determinare la qualità dei risultati. Caratteristiche alla base sia della soddisfazione degli utenti che delle preoccupazioni e critiche che i motori di ricerca (e Google in particolare, come leader assoluto) sollevano, in termini di privacy, identità algoritmica, inferenze comportamentali, filter bubble, effetto di gatekeeping, ecc.
Gli algoritmi di ranking sono il cuore dei motori di ricerca, incorporano centinaia di parametri di valutazione, differenziano profondamente i motori di ricerca, spiegando non solo perché la stessa query di un utente fornisce risultati diversi su differenti motori di ricerca ma anche perché la stessa query, formulata da utenti diversi o in luoghi diversi, fornisce ancora risultati diversi, ordinati in maniera differente. La qualità dei risultati forniti dai motori di ricerca deriva da due attributi principali: la rilevanza delle pagine web (dei documenti in genere) rispetto alla query dell’utente e l’autorevolezza delle pagine web stesse, in termini di importanza e reputazione nel contesto globale di internet. La rilevanza è quindi query-dependent e correlata al ranking dinamico, mentre l’autorevolezza è correlata al ranking statico, query-independent e definito in fase di indicizzazione. Gli algoritmi di ranking combinano insieme ranking dinamico e statico, rilevanza e autorevolezza, nel presentare agli utenti i risultati della ricerca effettuata.
Gli algoritmi usati per determinare la rilevanza di una particolare pagina web (in formato HTML) assegnano un peso diverso ai vari possibili elementi di testo di una pagina: titolo, corpo, tag headings, meta tags, URL della pagina. Gli anchor text (testo associato al link) di altre pagine web che indirizzano alla pagina web in esame sono considerati parte della pagina stessa. Peso maggiore è assegnato alla URL, agli anchor text, al titolo e ai tag h1/h2 (sottotitoli). La presenza di un termine di ricerca all’interno di un elemento di testo della pagina web è poi valutata con algoritmi di information retrieval tipo TD-IDF, che misurano la maggiore o minore frequenza con cui il termine è presente nell’elemento di testo.
Gli algoritmi per misurare l’autorevolezza di una particolare pagina web si basano soprattutto sulla struttura dei link relativi alla pagina: i link in uscita, presenti nella pagina e che indirizzano altre pagine web, e i link in entrata, presenti nelle altre pagine web e che indirizzano la pagina in esame. I due algoritmi principali sono HITS e PageRank (proposto nel 1998 da Lawrence Page e Sergey Brin, i fondatori di Google). L’algoritmo HITS assegna ad ogni pagina un hub score e un authority score: pagine hub importanti sono quelle caratterizzate dalla presenza di numerosi link in uscita verso importanti pagine autority, pagine autority importanti sono quelle caratterizzate dalla presenza di numerosi link in entrata provenienti da importanti pagine hub. Tale algoritmo concretizza una relazione di mutuo rinforzo tra hub e autority. Un motore di ricerca che utilizza l’algoritmo HITS presenta risultati di ricerca privilegiando pagine con elevati hub score e authority score. Il PageRank è un algoritmo complesso, alla base del funzionamento di Google, ma ormai modificato e avanzato rispetto alla formulazione originale. Parte dal principio che una pagina web è importante se ha numerosi link in entrata provenienti da altre pagine web importanti. Anche qui c’è “una relazione di mutuo rinforzo tra le pagine: l’importanza di una certa pagina influenza ed è influenzata dall’importanza di altre pagine”, come Gyongyi e Garcia-Molina dicono in un loro saggio del 2005. In estrema sintesi il PageRank di una pagina web aumenta all’aumentare del numero di link in entrata e diminuisce all’aumentare del numero di link in uscita, ma diminuisce anche se mancano totalmente i link in uscita. Inoltre, il PageRank di una pagina web all’interno di un gruppo (una community) di pagine web può essere ottimizzato gestendo opportunamente i link in entrata e in uscita tra le pagine del gruppo. Un motore di ricerca che utilizza l’algoritmo PageRank organizza i risultati di ricerca privilegiando pagine con PageRank elevato.
Una conoscenza dettagliata delle modalità operative dei motori di ricerca e dei loro meccanismi di ranking è alla base delle tecniche di Search Engine Optimization (SEO) per promuovere un sito web aziendale attraverso i motori di ricerca, sia di quelle white hat SEO (best practices lecite e virtuose) che di quelle black hat SEO (manipolative e ingannevoli sul valore dei siti web).





{kind=link}
Facebook Comments