




Il Deep Web è la parte non”googlabile” della Rete, dove si svolgono anche commerci illeciti e dove giacciono inesplorati i dati: si tratta ad esempio di contenuti non HTML o pagine non collegate ad alcuna pagina web o siti banditi dai motori di ricerca. In questa terra di nessuno si trovano anche gli Open Data.
I cataloghi Open Data sono una sorta di raccoglitori di etichette. Ogni etichetta descrive sommariamente che cosa c’è nella scatola, ovvero che dati ci sono, ma per capire effettivamente che cosa contiene non c’è che da aprirla. Quindi un bel numero di click, se si è tanto fortunati da trovare un grafico o un’anteprima “parlanti”, oppure scaricarli, quindi aprirli ed interpretarli. Le etichette si possono ricercare, ma i dati no, sono invisibili a Google o ai motori di ricerca dei portali stessi. Lo spiega, in un recente articolo su Scientific America, Cesar Hidalgo, Professore al MIT e capo del dipartimento Macro Connections dove si lavora su come trasformare i dati in conoscenza.
La sensazione di vago timore e perplessità che si prova di fronte ai contatori dei portali Open Data che ci intimoriscono con i totali a 3, 4, 5 zeri è quindi più che giustificato. Aumenta vertiginosamente la quantità di informazione, ma i cataloghi sono sommari poco parlanti e, quando si arriva ai dati, la mente umana non contiene nè decodifica velocemente l’informazione numerica. Non siamo noi ad essere inadeguati, ci rassicura Hidalgo, è come se ci avessero abbandonati nel reparto magazzino dell’Ikea tra le scatole con i componenti ma senza avere la possibilità di visitare l’esposizione.
L’interpretazione dell’informazione numerica è un problema ben noto, a cui l’uomo ha trovato una risposta con artifici visuali i cui primi esempi risalgono ai tempi della rivoluzione industriale. Circa un secolo dopo, durante la guerra di Crimea, Florence Nighingale, nota per aver fatto dell’infermieristica una scienza ma anche studiosa di statistica, inventa una data viz per mostrare come le morti dei soldati in Crimea fossero dovute più alle malattie che alle ferite da guerra.
Si tratta di un tipo di diagramma, detto rose diagram, ancora oggi utilizzato in meteorologia. Grazie a questa rappresentazione particolarmente efficace (il blu sono le morti per malattia, rosso per ferite da guerra , nero non classificato) Florence Nightingale riuscì a persuadere dell’opportuinità di attuare adeguate politiche sanitarie per evitare morti inutili.
Tabelle, grafici, reti e mappe diventano nel XX secolo un linguaggio ben codificato, ma è con la potenza di calcolo dei computer che i diagrammi diventano interattivi. Oggi le visualizzazioni on line di dati sono un mezzo comunicativo attraverso il quale si raccontano le storie per il giornalismo specializzato. Sono numerose le iniziative tematiche che permettono di esplorare i dati: per citarne alcune in ordine sparso e senza pretesa di completezza, iniziative di notevole impatto sono Open Coesione, Open Bilanci, Open Expo, Open Spesa , Confiscati Bene, “Where does may money go”.
Ma torniamo al MIT Media Lab dove si costruiscono motori di visualizzazione per poter ricavare velocemente conoscenza a partire dall’interrogazione di grandi basi di dati, dalle visualizzazioni ad uso di dati economici fino al recentissimo DataUSA, impressionante generatore di visualizzazioni per Open Data.
Intorno al 2010 Hidalgo e Alexander Simoes applicano tecniche di design e scienze cognitive a grandi banche dati sulle esportazioni mondiali. Alla base ci sono le ricerche sullo sviluppo economico e la correlazione con la capacità di esportazioni differenziate elaborata dall’economista Ricardo Hausmann e nota come Product Space. Il risultato è notevole: nasce The Observatory of Economic Complexity per mostrare e far capire le connessioni che esistono tra i Paesi e i beni prodotti/esportati.
Si tratta di un sito dove si combinano un insieme di modelli di interrogazione per fare slicing dei dati, ovvero “affettare i dati”, formulando semplici domande (per esempio Che prodotti produce un paese? Dove vanno le esportazioni del prodotto Y dal paese X?). Si impiega in questo caso un generatore dinamico di visualizzazioni, realizzato con il framework javascript D3plus, che poggia su più banche dati aggiornate relative al commercio mondiale, con dati dal 1962. Tutte le visualizzazioni sono esportabili ed integrabili in altri siti. Vediamo ad esempio che cosa esporta l’Italia in Germania.
The Observatory of Economic Complexity: che cosa esporta l’Italia in Germania.
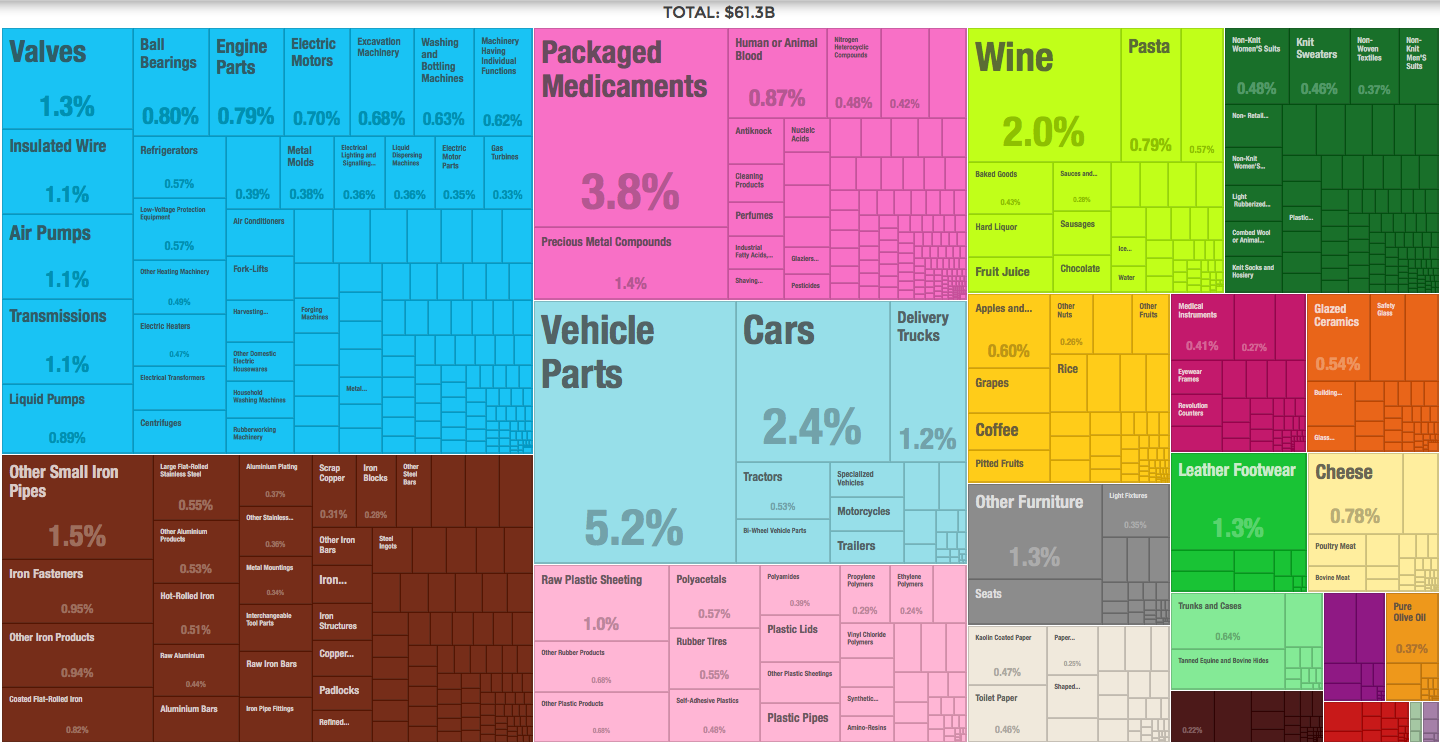
O dove sono le maggiori opportunità di esportazioni per l’Italia.

Diagramma a rete di tipo Product Space del mercato dei prodotti.
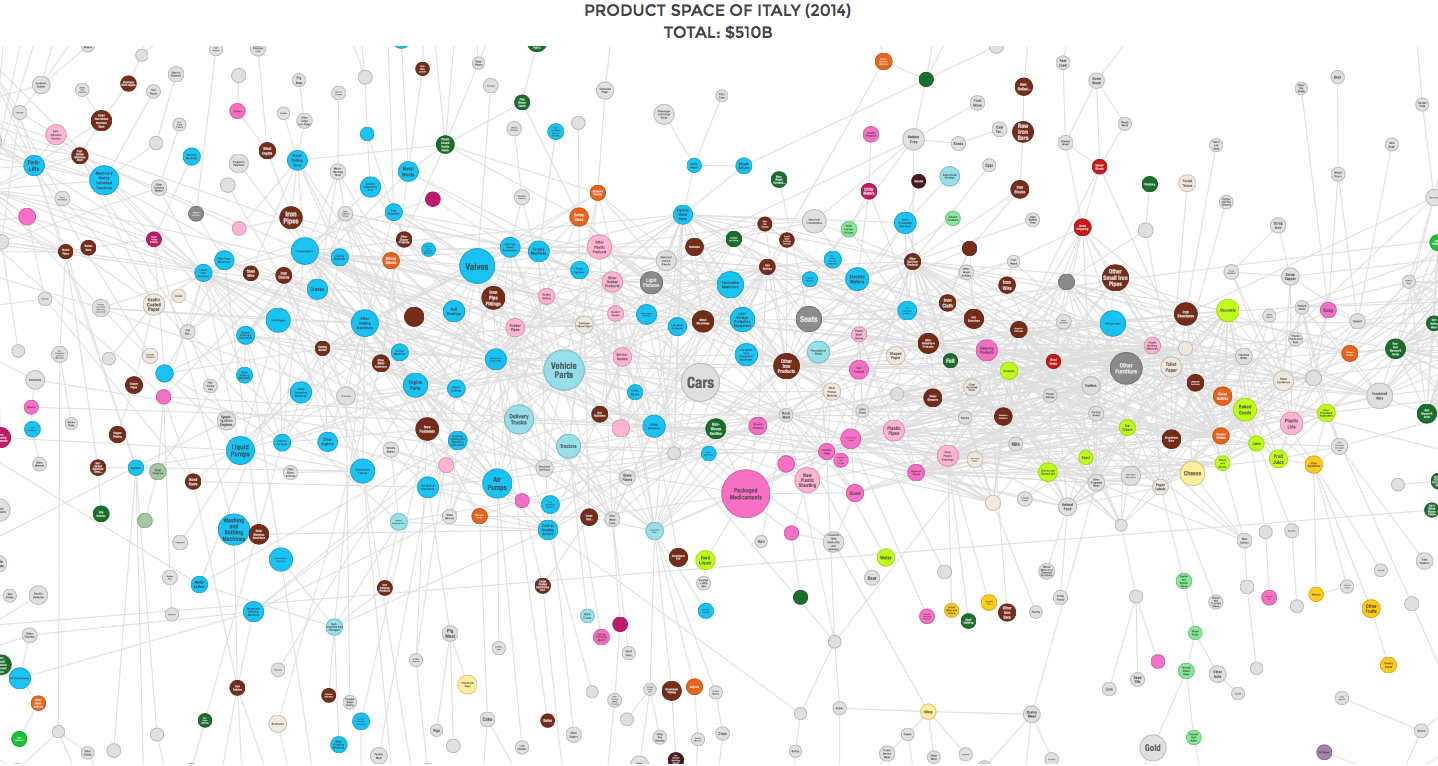
Si tratta di potenti visualizzazioni interattive che guidano dalla conoscenza generale del fenomeno ai dettagli e possono ispirare storie sui dati. Lo stesso principio è stato applicato nel 2013 per realizzare il portale Open Data brasiliano DataViva, dove si ricercano dati su società, economia e formazione. Si possono generare milioni di visualizzazioni interattive diverse, tutte aperte come anche i dati sottostanti. Vediamo come si distribuisce il lavoro nei settori produttivi per lo stato di Sao Paulo.
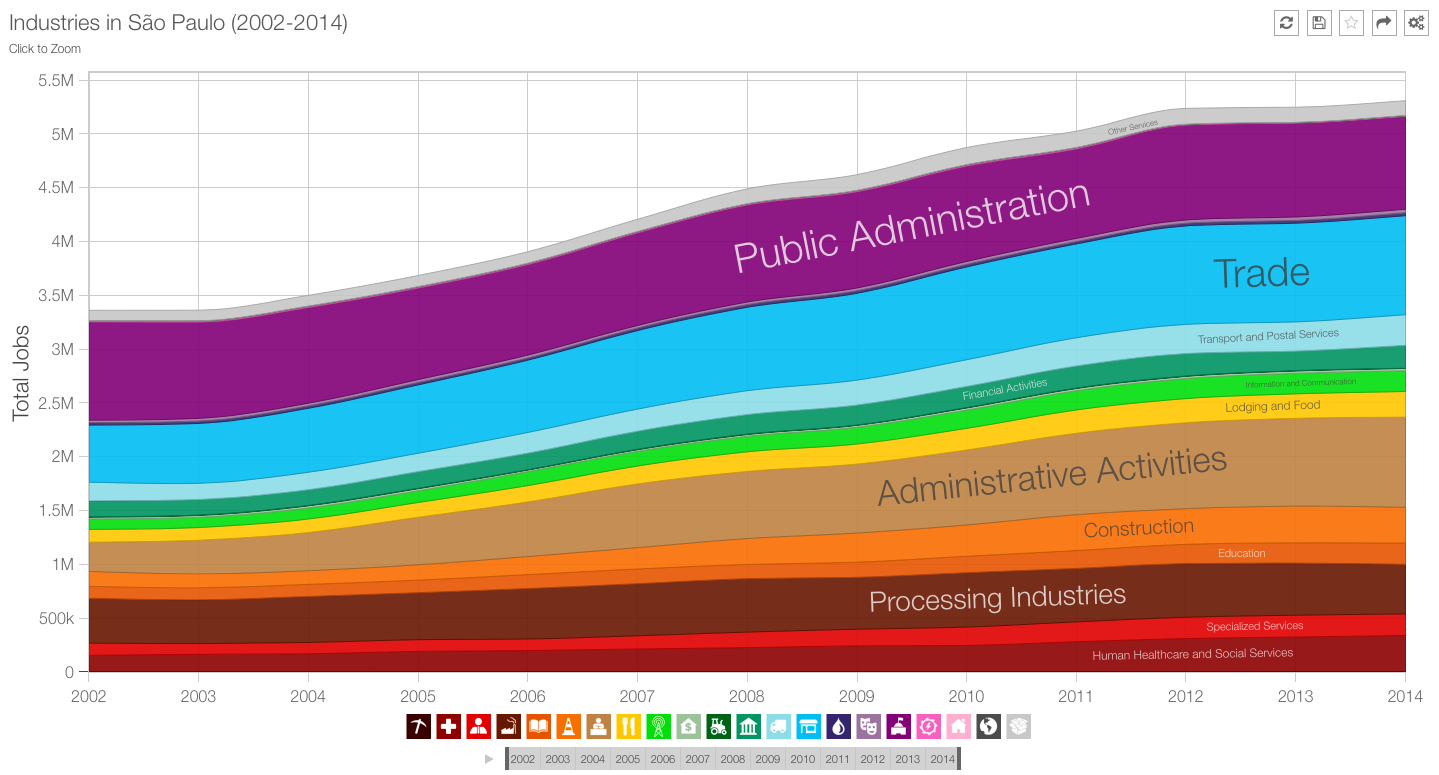
Ad aprile 2016 esce DataUSA, progetto realizzato ancora dal MIT insieme al colosso Deloitte, per mostrare gli Open Data americani.
DataUSA fonde ed elabora le banche dati di ministeri ed agenzie governative di statistica su lavoro, economia ed educazione. Rispetto alle precedenti esperienze è più curata la narrazione del dato a partire da contatori riepilogativi, fino ad analisi generate dinamicamente per 4 profili: geografico, produttivo, occupazionale, di formazione. Tutto si sviluppa in una sola pagina web con contatori e suggerimenti testuali in alto per orientare l’utente, quindi le visualizzazioni che presentano i dati secondo molti punti di vista, per arrivare a dettagli e dati scaricabili. È come avere un telescopio che dalle costellazioni visibili ad occhio nudo porta al massimo livello possibile di vicinanza. Grafica, immagini e dettagli sono molto curati e piacevoli. Tutti i dati sono scaricabili e interrogabili via API, le viz integrabili in altri siti ed esportabili in vari formati. Se si ricerca la città di New York si giunge ad un’unica pagina con 37 visualizzazioni dinamiche ed interattive che illustrano ognuna un diverso aspetto. Di seguito un diagramma su mappa con reddito per area geografica.
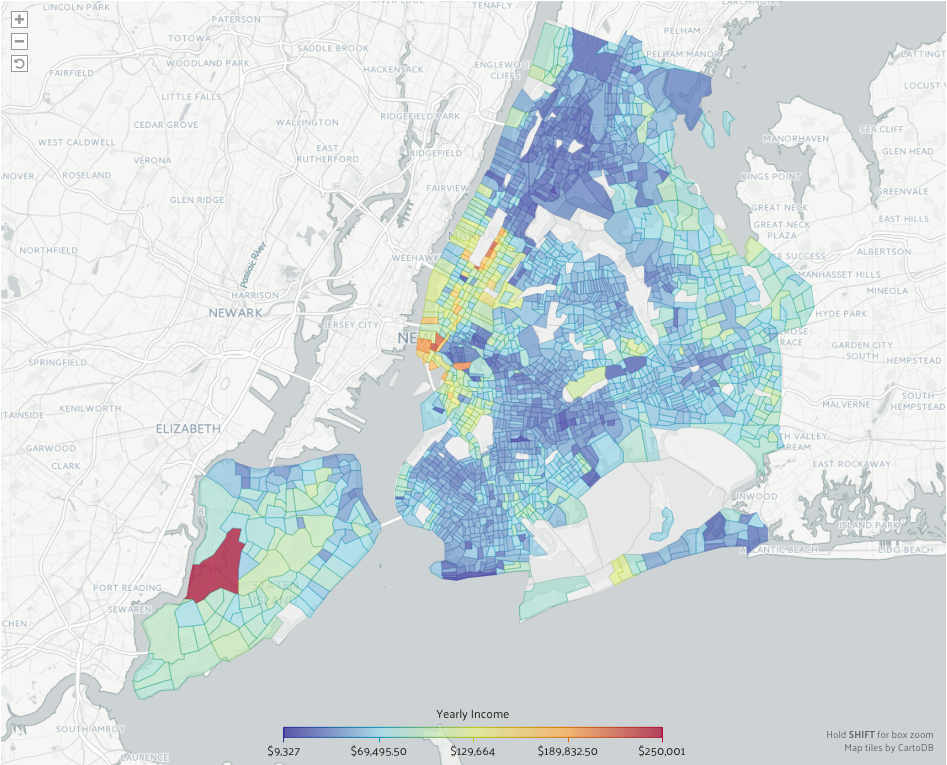
Non mancano né la sezione “Storie” con inchieste di tipo giornalistico a partire dalle visualizzazioni, nè la documentazione delle banche dati originarie, né classificazioni standard, nè come ottenere il dato grezzo con invocazione di API RESTful. Ci si può forse chiedere se la metodologia con cui sono fuse le varie banche dati possa portare a perdita di informazione rispetto ad analisi condotte sulle fonti originarie e non è documentato come siano gestite eventuali incompletezze o discrepanze delle fonti. Ma questo nulla toglie alla forza delle analisi auto-generate di DataUSA, splendida vetrina della conoscenza che si può trarre dagli anonimi scaffali dell’Open Data.
(Foto di cilipmarketing, CC BY-NC-SA 2.0)





{kind=link}
Facebook Comments