


















Si è fatto un gran parlare del consumo energetico, e della relativa carbon footprint, conseguenti al mining dei BitCoin: poiché il dispendio computazionale nell’attività di mining è notevole, il consumo energetico corrispondente lo è. E l’energia elettrica non solo costa in termini economici ma anche in termini ambientali.
L’energia si trasforma, ma con quale costo?
Come tutti ben sappiamo, o dovremmo sapere, l’energia non si crea (a differenza dei BitCoin!) né si distrugge, ma si trasforma soltanto: quando parliamo di generatori di corrente elettrica, per esempio, in realtà alludiamo a impianti che trasformano in elettricità un altro tipo di energia. L’esempio classico è quello degli impianti idroelettrici, che trasformano l’energia meccanica del movimento delle turbine, causato dalla caduta dell’acqua (e quindi a sua volta trasformato da energia potenziale in energia cinetica), in energia elettrica, che poi viene trasmessa lungo la rete.
Ogni trasformazione energetica in natura ha un costo, tipicamente pagato in due tipi di “moneta”: un po’ di energia viene dissipata, e si producono scorie.
Un tipico esempio è il corpo umano: un atleta che deve correre una maratona, converte l’energia chimica accumulata nelle sostanze contenute nei propri muscoli in energia cinetica: ma, come ognuno di noi sa (almeno da bambini tutti abbiamo corso!), quando si corre ci si accalda. Questo riscaldamento è la dissipazione di energia dovuta alla conversione da chimica a cinetica: semplicemente il calore che produciamo va sprecato anziché contribuire alla nostra corsa. Quanto poi alle scorie, sappiamo tutti che quando mangiamo non tutto quel che ingeriamo resta nel nostro corpo per essere utilizzato.
Dunque le cosiddette fonti energetiche sono in realtà convertitori di energia che, in quanto tali, tendono a dissipare e diminuire la propria capacità di conversione, fino all’esaurimento completo. Per esempio l’energia prodotta dal carbone è legata alla sua combustione che si utilizza per muovere delle turbine, convertendo quindi l’energia chimica del carbone in calore e questo in energia cinetica, che a sua volta tramite la turbina si converte in energia elettrica. In questa catena di trasformazioni, oltre alla dissipazione di energia, inevitabile in natura come abbiamo detto, si producono delle scorie, come il famigerato CO2, il diossido di carbonio.
Non tutte le trasformazioni energetiche producono sostanze dannose per l’ambiente, o comunque foriere di mutamenti che mettono a rischio la sopravvivenza di specie (non ultima la nostra), ma tutte, invariabilmente, dissipano energia. Anche le cosiddette “fonti rinnovabili” lo fanno, ma il loro consumo non è apprezzabile su scala umana. Per esempio, l’energia solare si può considerare una fonte costante e “perpetua”, perché il fatto che fra cinque miliardi di anni il sole non brillerà più non sembra un evento del quale preoccuparsi nell’immediato: parafrasando Keynes, nel lungo periodo saremo tutti morti. Invece i combustibili fossili, per quanto ancora largamente disponibili, sono sicuramente destinati ad esaurirsi nei tempi della storia umana.
Per questo motivo fonti energetiche come il sole, il vento, il calore terrestre, e così via sono considerate rinnovabili, vale a dire inesauribili rispetto alla scala temporale umana (che il vento debba esserci sempre in un punto del pianeta è poi conseguenza di un teorema di topologia che non stiamo qui a citare). Inoltre, queste fonti tipicamente non producono scorie dannose nel loro ciclo di trasformazione dell’energia, fatto salvo lo smaltimento degli impianti stessi (per esempio delle cellule fotovoltaiche, delle pale eoliche, etc.). Inoltre ciascuna di esse può produrre energia elettrica e, di fatto, l’energia elettrica che consumiamo è la “somma pesata” di energie trasformate da fonti diverse.
Per tutto quel che abbiamo ricordato fin qui, seppure in maniera un po’ semplicistica, è chiaro che l’uso di rinnovabili è da preferire alle altre fonti di energia, perché le scorie prodotte non sono dannose per l’ambiente o sono facilmente gestibili.
Pertanto l’optimum sarebbe se l’elettricità fosse tutta prodotta da fonti rinnovabili. Ma, ovviamente, non è così, per svariate ragioni, in parte ovvie. Come noto, le attività IT contribuiscono globalmente al 10% del consumo elettrico, e buona parte di questo 10% è dato dall’alimentazione dei dispositivi (computer, cellulari, etc.).
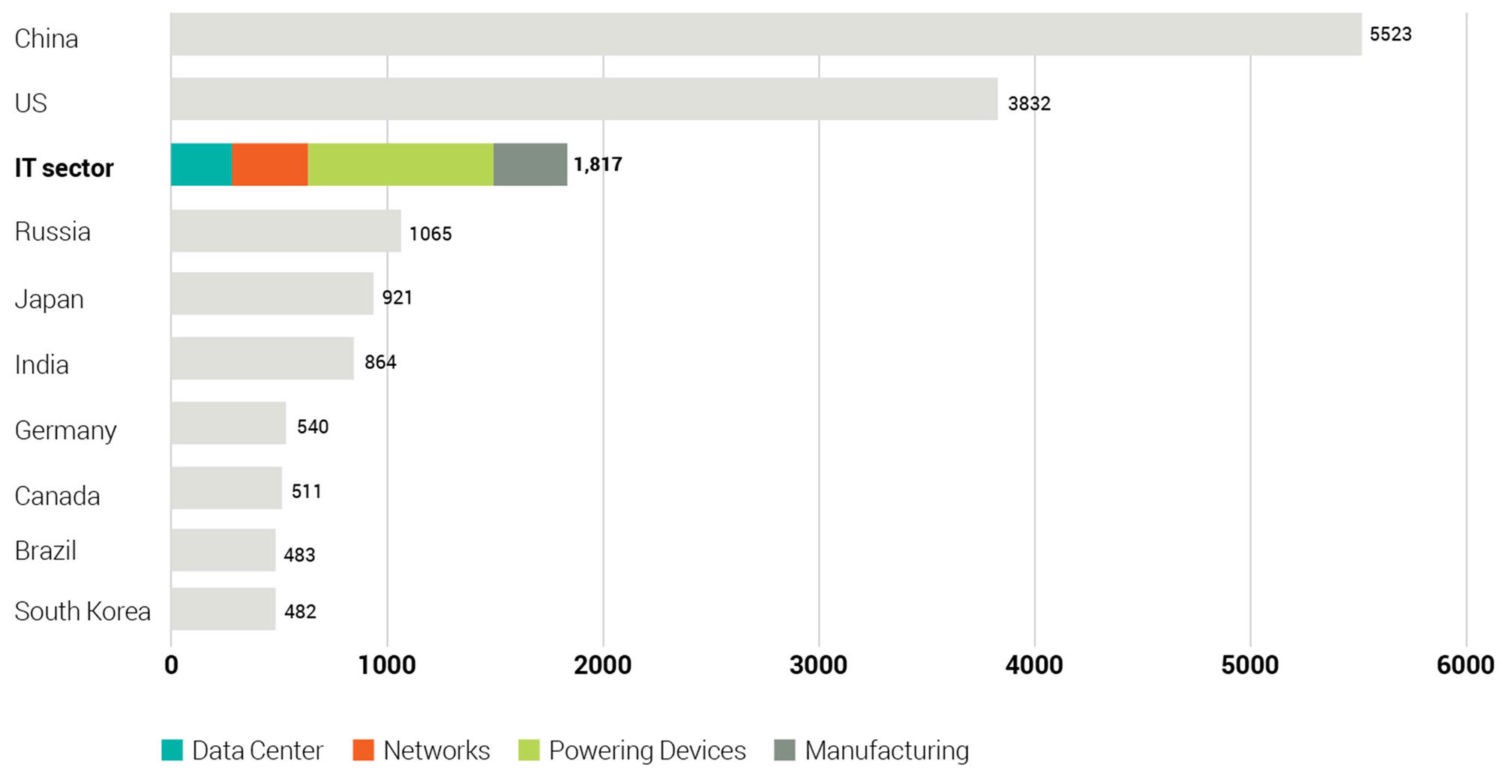
Fonte: Guillame Jacquart, “Digital Carbon Footprint — What can we do ?”
Deep Learning: ma quanto mi costi?
Abbiamo menzionato inizialmente il mining dei BitCoin, ma in effetti soltanto perché questa attività comporta calcoli lunghi e complessi: ma oggi esiste un’altra tecnologia pervasiva che ormai utilizziamo quotidianamente (e spesso inconsapevolmente) che richiede calcoli massivi e paralleli: il Deep Learning.
In particolare, il training di una rete neurale profonda e gli algoritmi di Deep Learning comportano invariabilmente l’utilizzo di tali reti, è un’attività che può essere molto dispendiosa computazionalmente, anche perché le reti di questo tipo dipendono da una serie di “iper-parametri” la cui calibrazione rispetto al problema da risolvere procede essenzialmente in modo empirico, per non dire a tentativi.
Questo vuol dire che addestrare una rete neurale profonda comporta in realtà riaddestrarla molte volte prima di trovare la sua parametrizzazione soddisfacente rispetto ai livelli di performance attesi.
L’impatto di questi calcoli è notevole. Inoltre, l’hardware necessario è spesso troppo dispendioso e quindi si utilizzano dei “computer provider”, cioè dei servizi web che consentono di dimensionare CPU e GPU a pagamento in modo da poter disporre, almeno nella fase di training e calibrazione degli iper-parametri, di potenza di calcolo sufficiente ai propri scopi. In questo modo chi svolge il calcolo non consuma direttamente energia elettrica per un dispositivo fisico, ma paga un servizio che la consuma per lui, attingendola evidentemente da dove fa più comodo al provider.
I dati sull’origine dell’elettricità di questi servizi sono interessanti: nel grafico seguente abbiamo comparato, fatto 100 il consumo di energia di una organizzazione, la ripartizione percentuale dell’origine dell’energia elettrica consumata da tre grandi Stati e da tre grandi cloud provider:
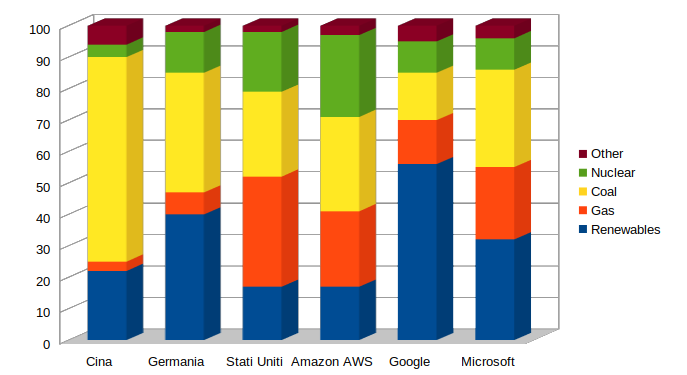
Dati da: Strubell, Ganesh, McCallum, Energy and Policy Considerations for Deep Learning in NLP
Come si vede, da un lato alcuni Stati sono ancora molto ancorati ai combustibili fossili, come la Cina, altri sono ormai orientati anche alle rinnovabili (l’Italia è fortunatamente fra essi). Pertanto un data center in Cina o in Germania, a parità di consumi annui, avrà un impatto ambientale diverso, e questo vale quindi per i provider che concentrano le loro server farm in luoghi dove magari l’energia costa meno ma è di dubbia provenienza, per così dire.
Notiamo in particolare la percentuale di nucleare e carbone che alimenta i servizi Amazon, molto usati per addestrare e far funzionare reti di deep learning.
Un interessante e rigoroso studio apparso di recente, calcola in particolare la carbon footprint di alcuni algoritmi di NLP (Natural Language Processing), utilizzati per esempio nella traduzione automatica da una lingua all’altra.
Ricordiamo che la carbon footprint è una misura, espressa solitamente in tonnellate di CO2 equivalente, delle emissioni totali causate direttamente o indirettamente da una certa attività nel suo ciclo di vita. Per esempio un’automobile ha una carbon footprint legata alla sua intera vita, ma chiaramente è possibile calcolare la carbon footprint limitata a un certo periodo di tempo, per esempio un anno. Per farlo nel caso dei sistemi IT è necessario avere le informazioni sull’origine dell’elettricità utilizzata e approntare un modello di stima, che è quanto viene fatto nel summenzionato articolo.
I risultati sono interessanti e sintetizzati parzialmente nella seguente tabella:
|
ACTIVITY |
CO2 EMISSIONS (Tons) |
|
Air travel, 1 passenger, NY->SF |
0,9 |
|
Human life (average), 1 year |
5 |
|
American life (average), 1 year |
16.4 |
|
Car (average) included fuel, 1 lifetime |
57.15 |
|
NLP Transformer training |
0.09 |
|
NLP BERT training |
0.65 |
|
NLP Neural Architecture Search training |
284.02 |
Le prime quattro righe contemplano attività non IT: un passeggero che viaggia da New York a San Francisco, un anno di vita umana, un anno di vita di uno statunitense, l’intera esistenza di una automobile.
Le ultime tre righe mostrano le emissioni del training di tre algoritmi di NLP, dei quali l’ultimo è particolarmente complicato e oneroso computazionalmente, in quanto comporta la “scoperta” dell’architettura migliore di una rete neurale da parte di un’altra rete neurale (semplificando molto): e, come si vede, il costo ambientale è elevatissimo.
Quali conclusioni si possono trarre da questi dati?
Come tutti gli studi seri, anche l’articolo di Strubell, Ganesh e McCallum offre delle soluzioni e non soltanto dati preoccupanti: in particolare si suggeriscono policy di comunicazione e standardizzazione delle calibrazioni degli iper-parametri in modo da non far ripetere “esperimenti” già provati da altri e per i quali sono disponibili i risultati.
Inoltre si pone l’accento su come la media degli algoritmi abbiano ancora una carbon footprint inferiore alla tonnellata, ma stiamo parlando del training di un singolo modello e non del suo utilizzo in fase di inferenza. In ogni caso sta emergendo un dibattito fra chi questi calcoli ha necessità di svolgerli, e la speranza è che una maggiore consapevolezza possa portare a un minore spreco di risorse ambientali da parte di reti neurali profonde: non c’è che da sperare che l’intelligenza artificiale si riveli più lungimirante e rispettosa dell’ambiente di quella umana.